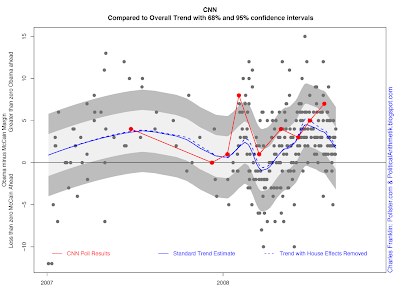
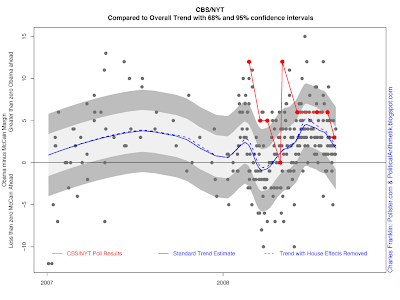
@A Lone Voice,
A Lone Voice wrote:
First off, the poll was conducted with a "random sampling" of 916 registered voters. Fair enough. But in their sampling, the Post interviewed what was eventually self-identified as leaning 54% dem and 38 % repub.
Huh? [..] This certainly isn't reflected in national party registration figures. Maybe in California.
Yeah. If you dial a random thousand people, that doesnt necessarily mean you always get a representative thousand people. There's always going to be outliers.
On the party ID in particular, though, note that pollsters usually dont ask about party registration (what are you registered as), but just about what the respondent considers him/herself as. Making for a much more fluid indicator. If the climate is very favourable to one party -- or even if things are going very favourably for one party in this particular week -- the number of self-described partisans of that party may swing up too.
But again, there's also just the random statistical variation which means you might just get an oversampling of one party's supporters in your sample this week - and an oversampling of the other party's backers in another week.
That's where weighting comes in. That's a whole debate among pollsters: to weight or not to weight? Proponents of weighting the data argue that a pollster has the responsibility to do his best to assure his sample is representative for the overall population, and to nip statistical aberrations in the bud that way. From what I understand they do this regularly enough for other indicators (age, gender, etc). So it doesnt matter if their sample has an apparent oversample of 65+ voters, because they weight the total results of that age group and other age groups to better represent what their actual share of the voters will be.
Even for something as unambiguous as age, though, this already has pitfalls: what if turnout among young voters is much higher, proportionally, this year than in previous years? Then weighting the data on the basis of track records will make you miss the impact of an important development this year.
OK, move that discussion to the question of party ID and you can see the controversy. Weighting the results by party ID, so that the preferences of the Democrats in your sample are weighted on the basis of what you'd expect the share of Democrats to be this year in the actual elections, will help you smooth out any volatile deviations if your sample ends up having a disproportionate number of Dems. But what if a lot more people simply are identifying themselves as Dems right now; what if the apparent oversampling of Dems in your sample signals that hey, there's a ground swell towards Democratic self-identification going on? Then weighting your data makes you miss that.
I dont know that there's a definite answer to who is right. I dont even know whether the ABC/WaPo poll weights their results. But keep these things in mind next time you look at the party ID breakdown of a poll and rush to concluding that it must be a fixed poll of some sort. There's a fair chance of standard statistical variation yielding occasional weird party ID samples; and on top of that, the pollster might well already have taken that into account in calculating its public numbers by weighting accordingly.
Quote:The kicker? The post had an oversampling of 163 black voters. Now, isn't this far above the 13.4% of the general African-American population? Isn't it far above that part of the African American population registered to vote?
This is really the same question.
On the one hand, you can speculate that African-Americans will in fact come out to vote in much higher proportion than usual; in higher proportion than their share of all registered voters, as fewer registered black voters fail to turn out on election day than of registered white voters; in higher proportion than their share of the population.
On the other hand, if the sample includes a number of African-Americans far surpassing their share of the population, the pollster might well already have taken that into account, by weighting down the impact of that share of respondents in the total end result. Or it might not, and the public numbers you're looking at are marked by that statistical aberration and constitute an outlier - which still doesn't necessarily involve some kind of political plot.
What you might even come across is that a pollster
deliberately oversamples respondents from a minority group, in order to make the total from that group large enough to be able to make statistically reliable separate conclusions about their voting behaviour; and then weights the impact of their share of the total sample of respondents down again to fit the likely share of that group among actual voters.
All of which to say that, where you see signs of deliberate rigging of opinion polls, there could be any number of legitimate methodology issues at work.